*Por Dalton Oliveira, MBA
O mundo está rodeado de problemas a serem resolvidos ao mesmo tempo que as empresas precisam usar inovação para ofertar novos produtos e novos serviços para os seus clientes. Há uma série de tecnologias já disponíveis para serem combinadas por smart teams para dar suporte à liderança na tomada de decisão, gerentes para liderar equipes com mais eficiência, e execução fazer mais com menos. Os grandes desafios são: o real entendimento do problema a ser resolvido (ou da oferta de um novo produto ou serviço), o escopo da POC e do MVP, e principalmente quais ferramentas usar para resolver o problema em questão. O budget e a criação dos times envolvidos são temas que se entrelaçam. Para o tópico desse artigo, um time multidisciplinar com forte conhecimento e experiências prévias fazem a grande diferença. A gestão, a sua forma de liderar, e as tecnologias a serem adotadas completam o quebra-cabeças da Transformação Digital: pessoas + processos + tecnologias.
Não há dúvida de que ter em mãos informações de detecção de anomalia em tempo-real pode evitar grandes perdas em recursos financeiros, infra-estruturas, e na vida das pessoas. A detecção de anomalia em tempo-real é capaz de (mas não limitada a):
- Enviar notificação em tempo-real sobre queimadas em florestas e questões sobre o clima;
- Devido a comportamento anormal antes de um terremoto, enviar um alerta imediato sobre a evacuação em prédios inteligentes e cidades inteligentes;
- Manutenção preditiva em indústria antes da parada de um motor industrial;
- E diversas outras soluções que podem surgir (com as devidas adaptações) para dar suporte a rápida e assertiva tomada de decisão.
Nesse artigo será apresentada a aplicação de Machine Learning [ML] e Deep Learning [DL], com suporte de Internet das Coisas / Internet of Things [IoT] (para a coleta de dados e transmissão/recepção de dados e informações entre as camadas Edge, Fog, and Cloud Computing), para uma solução que roda a inferência dos dados em tempo-real afim de determinar a detecção de anomalia em Edge Computing usando EmbeddedAI.
Mas, primeiro, o tópico de Engenharia de Dados é a base devido a coleta de dados: algumas centenas de minutos de dados precisam ser coletados para compor os datasets de Treinamento e Teste afim de determinar os algoritmos de AI.
Considerando a variedade de técnicas que Machine Learning [ML] pode prover, algumas delas serão exploradas nesse artigo, como Classificação (Supervised Machine Learning) e Clustering / K-means (Unsupervised Machine Learning) para a detecção de anomalia. Em adicional, os tópicos Time Series [TS] e Deep Learning [DL] / Artificial Neural Networks [ANN].
Engenharia de Dados, Sistemas Embarcados, Internet das Coisas [IoT]
O termo EmbeddedAI (EdgeAI, EdgeML, TinyAI, ou TinyML) se dá devido aos algoritmos de ML e DL que serão executados localmente (na camada de Edge Computing) em um sistema eletrônico embarcado (Sistema Embarcado), para rodar a inferência dos dados em tempo-real resultando na classificação do comportamento “Normal” ou “Anomalia”.
Nesse artigo, a detecção de anomalia se dará mediante a análise de comportamento de um motor industrial, que a partir daqui será chamado de “equipamento”.
Para a coleta de dados do comportamento “Normal” do equipamento (cujas categorias são: “class33” e “class22”), um sensor do tipo acelerômetro (com 3 graus de liberdade [3DOF]) é fixado na carcaça do equipamento e conectado a um Microcontrolador [MCU] na camada de Edge Computing (Sistema Embarcado). A simulação do comportamento de “Anomalia” se dará quando algum outro tipo de comportamento ou perturbação (física ou elétrica) não conhecida previamente na fase de treinamento vier a ocorrer.
Em Produção, é aplicado o conceito “Sensor Fusion”, onde mais de um sensor é usado para caracterizar com mais elementos a classificação do comportamento “Normal” ou “Anomalia”. Em adicional a alguns sensores (vibração, sinal de áudio, visão computacional), é possível também considerar sensores de temperatura, umidade, pressão, luminosidade, diferentes tipos de gases, compostos orgânicos voláteis, entre outros.
Em relação a coleta de dados em si, outros fatores também são importantes para a escolha do Microcontrolador [MCU] (camada de Edge Computing) e o Single Board Computer [SBC] (camada de Fog Computing), como a escolha dos sensores e outros elementos que vão compor ambos os ambientes, e como os datasets serão criados. As características elétricas dos devices e sensores devem seguir o mesmo nível lógico adotado (5V ou 3V3) (caso contrário, um circuito auxiliar com conversor de nível lógico deverá ser montado), interfaces disponíveis e habilitadas (I2C para displays, SPI para RF/rádio, canais Seriais para outras comunicações), temperatura de trabalho, etc.
A arquitetura do sistema deve assumir uma abordagem de sistemas distribuídos para o melhor aproveitamento dos recursos computacionais, o que impacta diretamente na quantidade de dados coletados por segundo, por isso a quantidade de cores na CPU do MCU também é importante (neste caso, 32 -bit dual-core), conforme imagem mostrada na Figura 1.
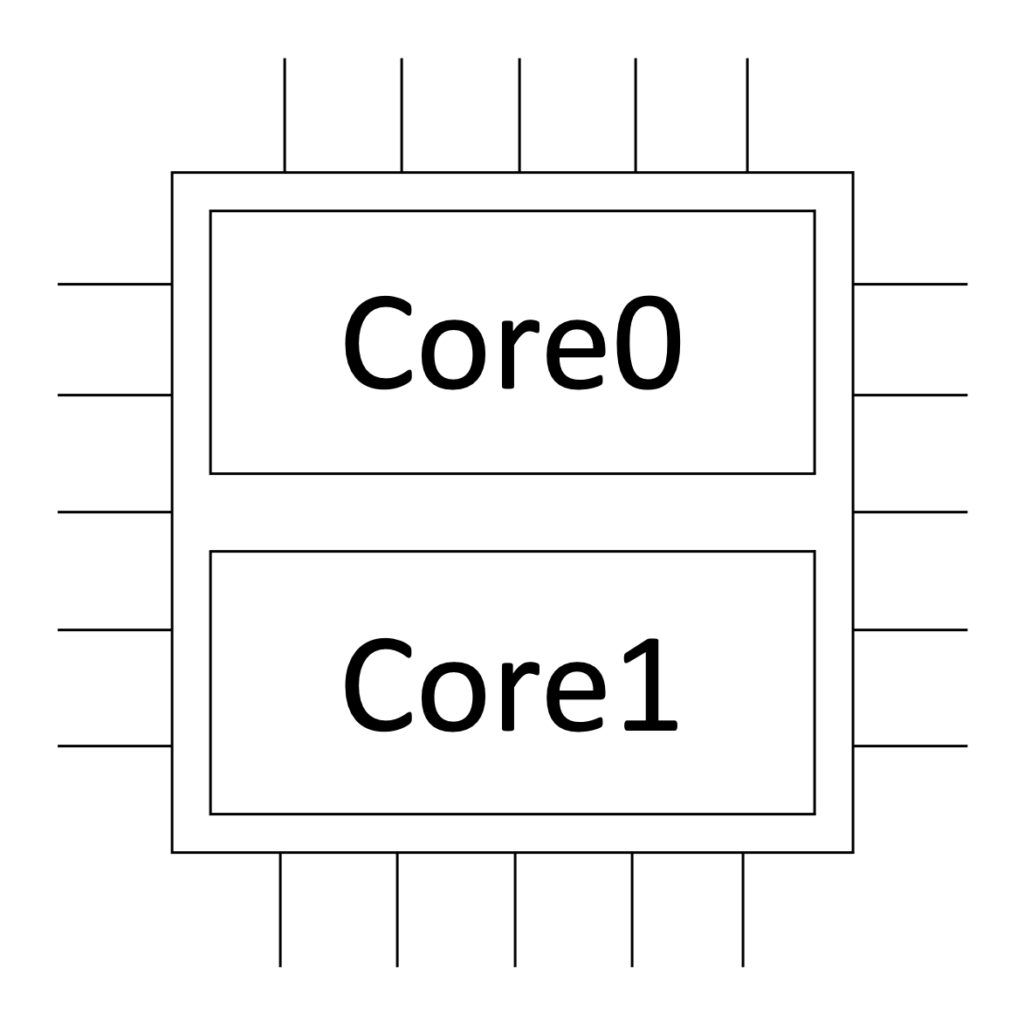
Figura 1. Quantidade de cores na CPU do MCU
Fonte: Wardston Consulting
A escolha do Microcontrolador [MCU] e do Single Board Computer [SBC] é fundamental para o sucesso da solução. A relação entre as camadas (Cloud, Fog, Edge) pode ser vista conforme imagem mostrada na Figura 2.
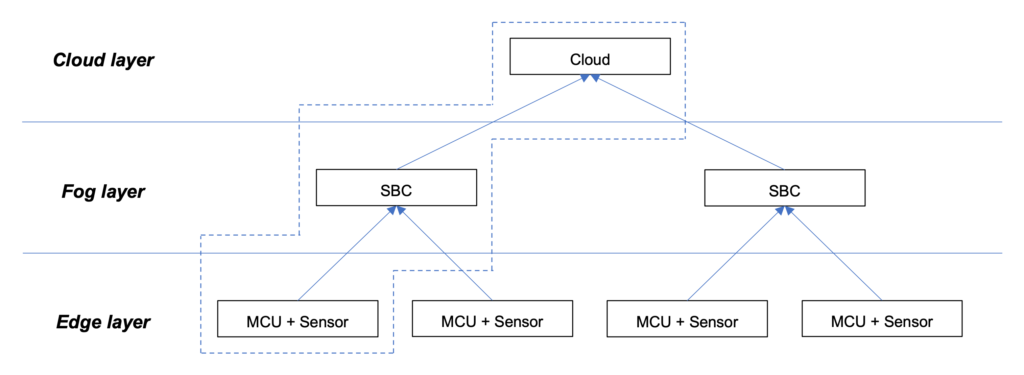
Figura 2. A relação entre as camadas (Cloud, Fog, Edge)
Fonte: Wardston Consulting
É mandatório que o ambiente de coleta de dados e o ambiente de inferência de dados sejam os mesmos.
Entrada de Dados, Processamento de Dados, Aprendizagem de AI
É importante ressaltar que embora as etapas de Treinamento e Teste sejam realizadas no ambiente de cloud (Cloud Computing) (para auxiliar no desenvolvimento, treinamento e teste dos algoritmos de AI), a inferência dos dados será realizada localmente no MCU (Edge Computing). Devido a isso, há uma diferença de abordagem quando comparada com a tradicional onde todos os passos são realizados em cloud. Uma vez que a inferência é realizada na camada de Edge Computing, é importante salientar que o MCU tem um menor poder de processamento quando comparado com o cloud, portanto, os hiperparâmetros de Machine Learning [ML] e a quantidade de neurônios de entrada e das camadas escondidas do Deep Learning [DL] / Artificial Neural Network [ANN] devem ser configurados afim de encontrar o ponto ótimo para equalizar a melhor qualidade dos resultados obtidos com o poder de processamento do MCU escolhido.
A configuração do projeto para a natureza do problema apresentado nesse artigo se dá com o uso de:
- Entrada de Dados: Time Series [TS] (algumas dezenas de arquivos .csv com dados coletados para compor os datasets de Treinamento e Teste);
- Processamento de Dados: Análise Espectral (para reduzir a dimensionalidade dos dados);
- Aprendizagem de AI: Classificação (Supervised Machine Learning) + Artificial Neural Network [ANN] Classifier (Deep Learning) + Detecção de Anomalia (Clustering / K-means) (Unsupervised Machine Learning).
O processo de coleta de dados será repetido até a obtenção da Acurácia entre 70% – 90% nos dados de Treinamento e nos dados de Teste, onde o “Fit” é caracterizado para uma boa inferência dos dados em Produção. As faixas “Underfit”, “Fit”, e “Overfit” do modelo são apresentadas na Tabela 1.
Tabela 1. Faixa de “Underfit”, “Fit”, e “Overfit” do modelo

Fonte: Wardston Consulting
Lembrando que:
- “Underfit”: quando o modelo não consegue capturar dados de tendência;
- “Fit”: quando o modelo captura dados de tendência e é capaz de generalizar quando exposto a dados não treinados;
- “Overfit”: quando o modelo captura dados de tendência, mas não é capaz de generalizar quando exposto a dados não treinados.
É importante sempre seguir a proporção 80/20 para Treinamento e Teste para cada uma das categorias (“class33” e “class22”). Neste caso, os datasets foram criados a cada 10 segundos em 91Hz ou 11ms até completar o tempo necessário para atingir o “Fit”, conforme Tabela 2.
Tabela 2. Tempo necessário para os cenários de Treinamento e Teste para cada uma das categorias

Fonte: Wardston Consulting
Para completar o tempo necessário para Treinamento e Teste de cada cenário e de cada uma das categorias (“class33” e “class22”), os datasets foram criados em arquivos .csv, conforme mostrado na Tabela 3.
Tabela 3. Datasets em arquivos .csv para os cenários de Treinamento e Teste para cada uma das categorias

Fonte: Wardston Consulting
Se cada arquivo de 10 segundos em 91Hz ou 11ms contém 910 leituras, foram necessárias as seguintes quantidades de leituras para Treinamento e Teste para cada cenário e cada uma das categorias (“class33” e “class22”), conforme mostrado na Tabela 4.
Tabela 4. Número de leituras dos cenários de Treinamento e Teste para cada uma das categorias

Fonte: Wardston Consulting
Na entrada dos dados foi considerada uma janela de amostragem de 1 segundo para cada categoria. Considerando, por exemplo, a categoria “class33”, os dados da janela de 1 segundo são apresentados na Tabela 5.
Tabela 5. Categoria “class33” em uma janela de amostragem de 1 segundo

Fonte: Wardston Consulting
Como há dados em todos os 3 eixos (accX; accY; accZ), a janela de amostragem de 1 segundo exibe 273 raw data (91 raw data x 3 eixos).
No processamento de dados, a análise espectral desempenha o papel de reduzir a dimensionalidade dos dados, transformando os dados no domínio do tempo (em milissegundos) para o domínio da frequência (em Hz). Um tópico altamente complexo que utiliza Processamento Digital de Sinais [DSP] e técnicas relacionadas ao processamento de amostras de sinais discretos.
A vantagem da Feature Extraction é transformar Raw Data em Features que são processados com maior eficiência, conseguindo manter as características dos dados originais. Lembrando que Feature é a característica de um fenômeno observado. O resultado da Feature Extraction são 33 features (11 features x 3 eixos).
De acordo com o obtido na Feature Extraction (33 features), algumas diferentes arquiteturas de Redes Neurais Artificiais [ANN] foram experimentadas para construir o ANN Classifier. Para balancear a carga de todos os elementos envolvidos (escopo e recursos do projeto, resultado esperado como produto digital, e melhores práticas), a configuração final é a mostrada abaixo:
- 1 camada de entrada com 33 neurônios;
- 2 camadas escondidas:
- Primeira camada escondida com 20 neurônios;
- Segunda camada escondida com 10 neurônios.
- 1 camada de saída com 2 neurônios que representam as duas categorias (“class33” e “class22”).
Para a configuração do projeto considere o diagrama de blocos com todos os elementos interligados, conforme imagem mostrada na Figura 3:
- Entrada de Dados: Time Series [TS];
- Processamento de Dados: Análise Espectral – Feature Extraction;
- Aprendizagem de AI: Classificação (Supervised Machine Learning) + Artificial Neural Network [ANN] Classifier (Deep Learning) + Detecção de Anomalia (Clustering / K-means) (Unsupervised Machine Learning).

Figura 3. Configuração do projeto e todos os elementos interligados
Fonte: Wardston Consulting
Resultados
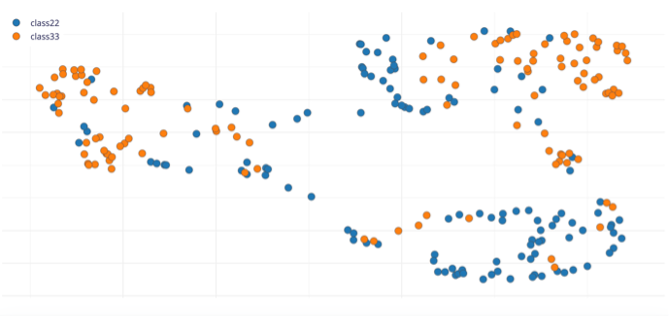
Com as amostras de dados em cada um dos cenários apresentados na Tabela 4, foram obtidas boas separações das categorias (“classe33” e “classe22”) em Clusters.
Considere as seguintes Generated Features com separação de categorias (“class33” e “class22”) em Clusters para cada cenário conforme imagem mostrada na Figura 4.

Fonte: Wardston Consulting
Considere os seguintes Dados de Treinamento com separação de categorias (“class33” e “class22”) em Clusters para cada cenário conforme imagem mostrada na Figura 5.
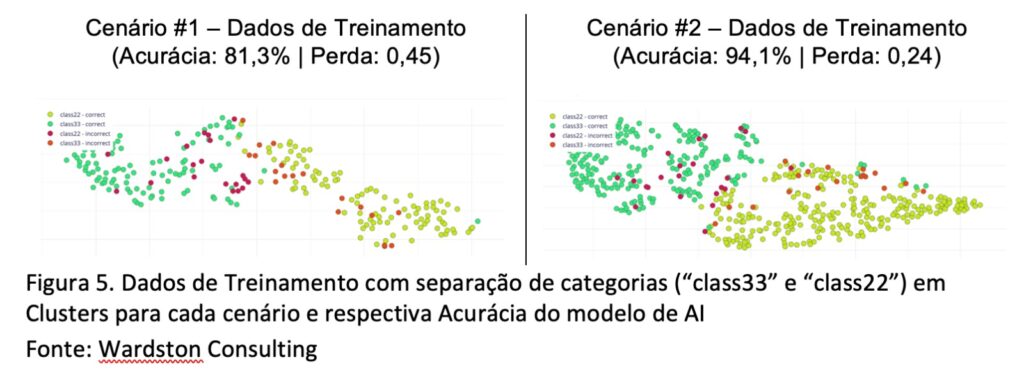
Considere os seguintes Dados de Teste com separação de categorias (“class33” e “class22”) em Clusters para cada cenário conforme imagem mostrada na Figura 6.
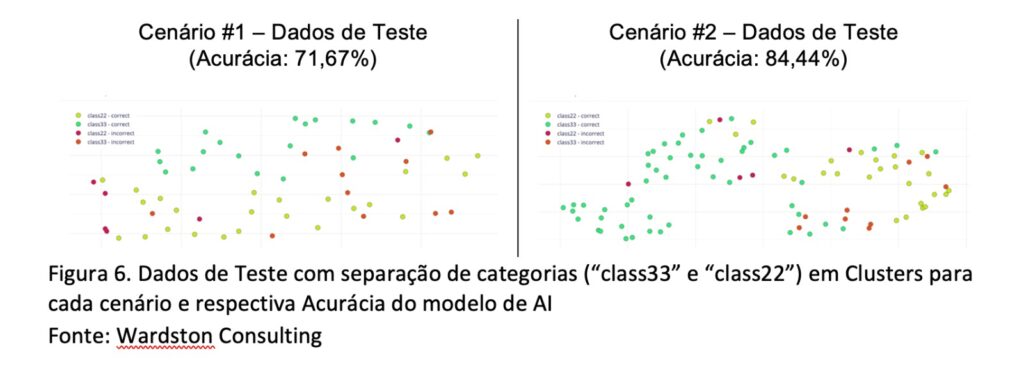
Pela análise entre o Cenário #1 versus o Cenário #2, é possível considerar que o Cenário #2 se ajusta melhor ao objetivo deste artigo.
Conclusão
O “como” superar os desafios mencionados no início do artigo fazem a diferença para o sucesso da entrega. E, como se pode notar, o tema é bastante complexo, o que exige uma abordagem multidisciplinar: Data Science e Engenharia (Elétrica, Eletrônica, Hardware, Software, Cloud/Fog/Edge, Banco de Dados, Telecom/Redes, e afins) para o uso correto das técnicas e ferramentas de gerenciamento, desenvolvimento e implantação.
Existem outras maneiras de lidar com a detecção de anomalia. Então, por que escolher esse método ? Apesar de ser um método refinado, a coleta de apenas algumas dezenas de minutos de dados e o touchbase de sistemas distribuídos representam economia de recursos financeiros e de tempo de projeto, além de robustez e confiabilidade dos resultados baseados na Acurácia.
Dito isso, a aplicação de Engenharia de Dados, o suporte de um ambiente de cloud no desenvolvimento, treinamento e teste de algoritmos de Machine Learning [ML], Deep Learning [DL] / Artificial Neural Network [ANN] para rodar a inferência de dados em tempo-real, com o apoio da Engenharia e da Internet das Coisas [IoT], demonstram os benefícios da abordagem adotada e compõem uma solução que agrega valor para qualquer segmento da indústria com as adaptações necessárias. Fica claro que, para cada use case, há necessidade de análise contextual e de um projeto customizado, não sendo recomendada a reprodução total ou parcial dos dados, algoritmos, parâmetros, e/ou qualquer outro elemento gerado para a inferência dos dados mencionados acima.
Sobre o autor:
Dalton Oliveira, MBA é Advisor Global em Transformação Digital, Board Member, Mentor, Palestrante, Autor/Escritor, Membro de Júri em Premiações Internacionais na Wardston Consulting. Premiado internacionalmente com Top 3 IoT World Series, Facebook Testathon Best Product Idea, entre outros. Membro do Conselho Consultivo da ABINC. Experiência na liderança de aplicações, soluções, PMO globais de missão-crítica em iniciativas estratégicas, atuando como head em grupos compostos por executivos e gerentes de equipes multidisciplinares, multiculturais, remotas a fim de implementar soluções de cloud/edge de valor agregado (incluindo AI/ML, IoT, Geo) para atender a estratégia de growth em empresas globais líderes em seus segmentos, governos, universidades desde 2002. Graduação em Engenharia Elétrica (FEI Engenharia) e MBA em Data Science & Analytics (USP).
LinkedIn (www.linkedin.com/in/daltonrdo)
Wardston Consulting (www.wardston.com)